# HELP process_start_time_seconds Start time of the process since unix epoch. # TYPE process_start_time_seconds gauge process_start_time_seconds 1.581927873353E9 # HELP jvm_threads_states_threads The current number of threads having NEW state # TYPE jvm_threads_states_threads gauge jvm_threads_states_threads{state="runnable",} 9.0 jvm_threads_states_threads{state="blocked",} 0.0 jvm_threads_states_threads{state="waiting",} 13.0 jvm_threads_states_threads{state="timed-waiting",} 2.0 jvm_threads_states_threads{state="new",} 0.0 jvm_threads_states_threads{state="terminated",} 0.0 # HELP process_files_open_files The open file descriptor count # TYPE process_files_open_files gauge process_files_open_files 96.0 # HELP system_load_average_1m The sum of the number of runnable entities queued to available processors and the number of runnable entities running on the available processors averaged over a period of time # TYPE system_load_average_1m gauge system_load_average_1m 1.30322265625 ...
可以看到这些数据是符合 prometheus 定义的数据收集的格式的,默认提供了 jvm, cpu 和 web 等方面的指标 我们给 web 应用定义了 /index,/recommend 的接口,访问一下这些接口后再看看 /actuator/prometheus的输出结果,发现多了
1 2 3 4 5 6 7 8 9 10 11 12 13
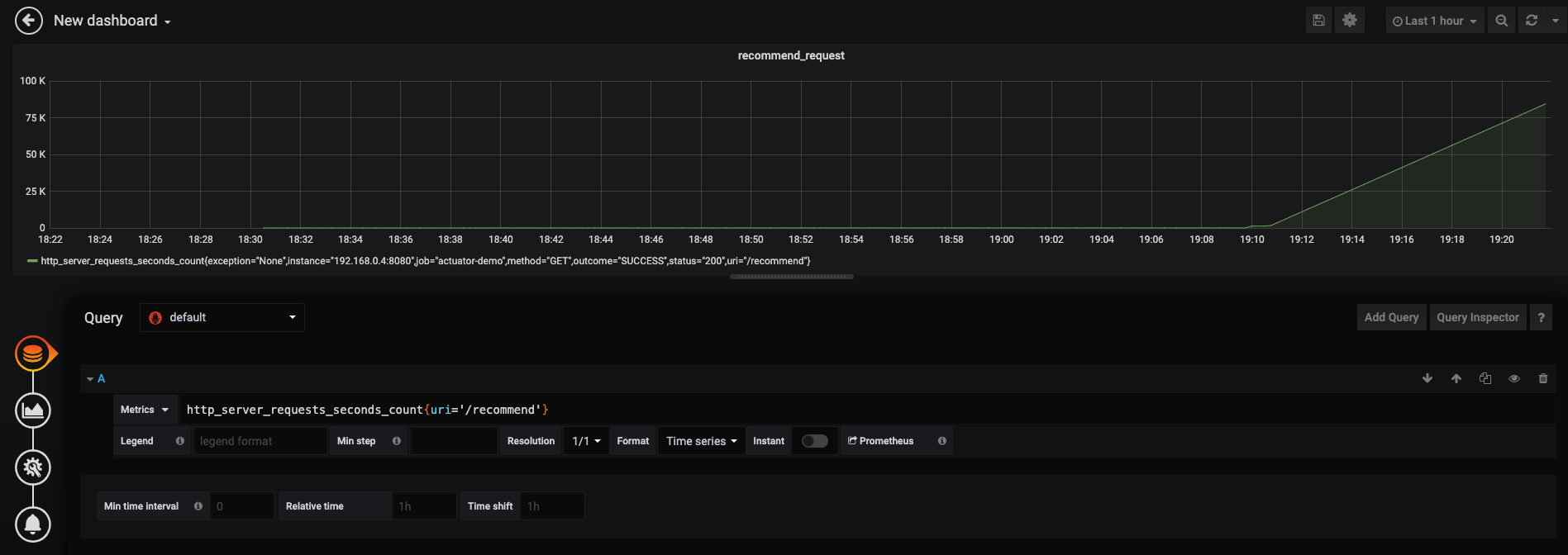
# HELP http_server_requests_seconds # TYPE http_server_requests_seconds summary http_server_requests_seconds_count{exception="None",method="GET",outcome="SUCCESS",status="200",uri="/index",} 1.0 http_server_requests_seconds_sum{exception="None",method="GET",outcome="SUCCESS",status="200",uri="/index",} 0.013830247 http_server_requests_seconds_count{exception="None",method="GET",outcome="SUCCESS",status="200",uri="/actuator/prometheus",} 3.0 http_server_requests_seconds_sum{exception="None",method="GET",outcome="SUCCESS",status="200",uri="/actuator/prometheus",} 0.071013869 http_server_requests_seconds_count{exception="None",method="GET",outcome="SUCCESS",status="200",uri="/recommend",} 1.0 http_server_requests_seconds_sum{exception="None",method="GET",outcome="SUCCESS",status="200",uri="/recommend",} 0.092041806 # HELP http_server_requests_seconds_max # TYPE http_server_requests_seconds_max gauge http_server_requests_seconds_max{exception="None",method="GET",outcome="SUCCESS",status="200",uri="/index",} 0.013830247 http_server_requests_seconds_max{exception="None",method="GET",outcome="SUCCESS",status="200",uri="/actuator/prometheus",} 0.056484717 http_server_requests_seconds_max{exception="None",method="GET",outcome="SUCCESS",status="200",uri="/recommend",} 0.092041806
# HELP recommend_timer_recall_seconds_max # TYPE recommend_timer_recall_seconds_max gauge recommend_timer_recall_seconds_max 0.0 # HELP recommend_timer_recall_seconds # TYPE recommend_timer_recall_seconds summary recommend_timer_recall_seconds_count 2.0 recommend_timer_recall_seconds_sum 0.05997796
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s).
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus'
# metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090']